

It is one thing to build a chatbot in a Jupyter notebook. It is another thing entirely to architect and deploy a secure, scalable, and reliable AI service. This is how we built the YUX Academy AI Assistant from a simple prototype to a production-ready Retrieval Augmented Generation (RAG) system on Google Cloud, designed to leverage the academy’s rich but scattered internal knowledge base.
The Problem
YUX Academy has spent years generating high-value content across a variety of formats, including detailed training materials and reports in PDF documents, visual Miro boards, Google Slides presentations, and the public case studies featured on our website. This knowledge is the backbone of our Human Centred Design (HCD) training programs. But as the corpus grew, information became siloed and increasingly difficult to search efficiently.
Hence, the clear vision for the assistant was that it needed to act as an internal productivity tool. One that could help our teams quickly prepare new training materials, draft workshop agendas, and instantly find relevant YUX case studies for proposals and reports. It needed to function as a digital assistant drawing exclusively from our internal knowledge base to provide fast and accurate answers.
Going from a Prototype to Full Stack Architecture
The Kaggle Experiments
The project began on Kaggle, where we experimented with open-source large language models like Llama 3 8-B Instruct and Microsoft’s Phi-3. These models were chosen for their instruction-following capabilities and their availability as free, open-source solutions, which was an important factor during the prototyping phase.
However, we quickly faced two major roadblocks. Firstly, performance bottlenecks. Llama 3 8-B, running on Kaggle’s shared infrastructure was prohibitively slow. The model required a lot of GPU memory and processing power, leading to response times measured in minutes rather than seconds. This was unacceptable for a real-time professional tool.
Secondly, quality concerns. The responses generated by smaller models like Phi-3 did not meet the standards required for an internal knowledge assistant. They lacked the nuance and contextual understanding necessary for our use case.
These challenges forced a pivot to enterprise-grade infrastructure and more capable models.
Migration to Google Cloud Platform
Moving to GCP, we completely reimagined the architecture. We decided on a modern, serverless, microservices-based design that would leverage managed AI services while maintaining cost efficiency and scalability.
For the Frontend, we built a user interface using React and TypeScript, prioritising user experience from the ground up. The interface features real-time response streaming with a “Stop Generating” option, a clean welcome screen with prompt starters to guide users, and a comprehensive settings panel that allows users to control response length, toggle conversational context, and manage their chat history. Authentication flows through Firebase with Google Sign-In, providing both security and convenience.
The FastAPI-based backend orchestrates the entire RAG pipeline. Built in Python for its asynchronous capabilities and excellent AI ecosystem, the backend handles query processing, retrieval, generation, and data persistence. Firebase Authentication validates user identity through ID token verification, while Cloud Firestore in Datastore Mode manages conversation histories.
Both services are containerized with Docker and deployed to Cloud Run, Google’s serverless container platform. This architecture automatically scales down to zero during periods of inactivity to ensure we only pay for what we use.
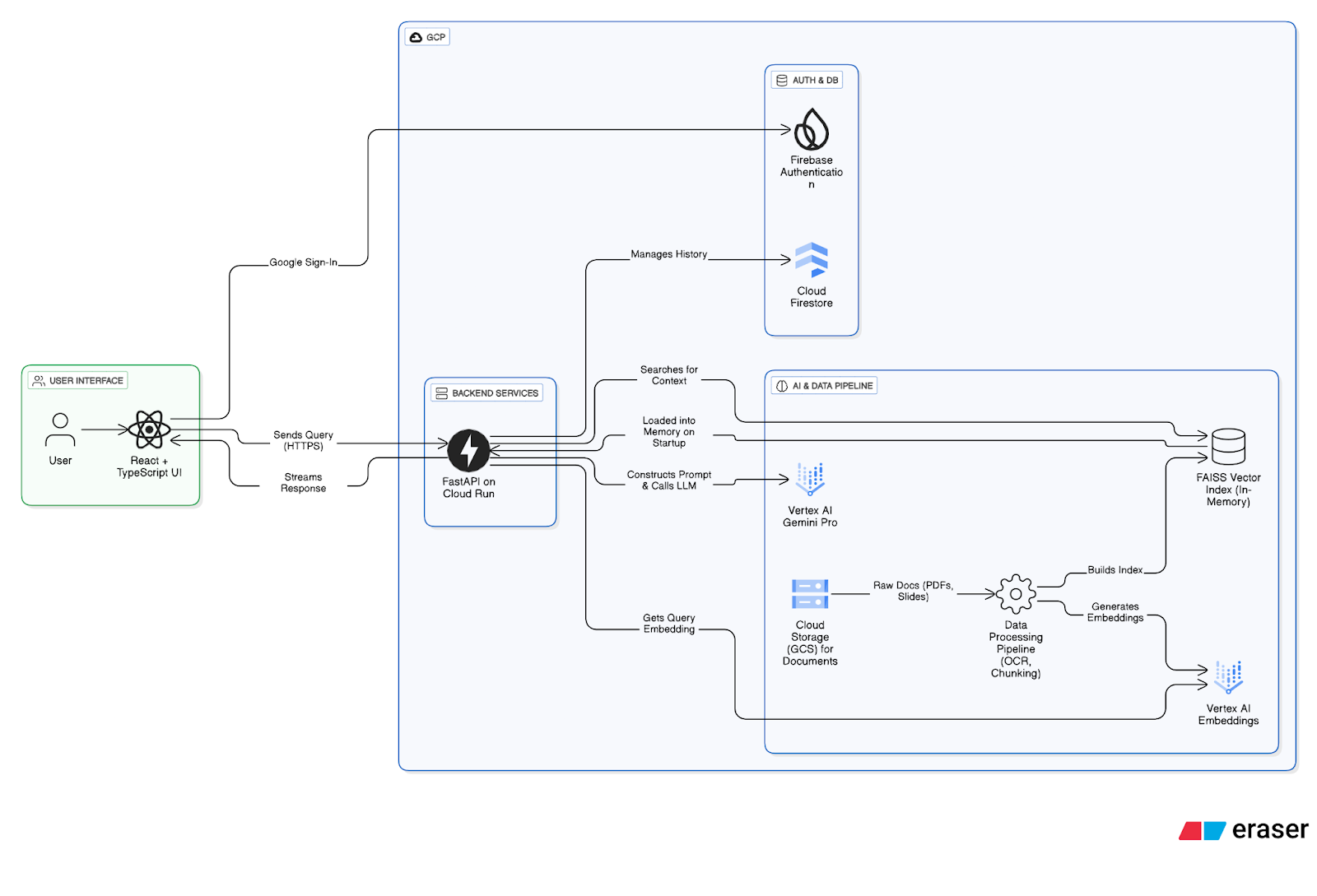
Wrestling with Data
One of the project’s biggest challenges was transforming diverse source materials into a usable knowledge base. Our corpus included traditional documents, but also visual heavy formats like Miro boards and slide presentations which cannot be processed using straightforward text extraction.
Experimenting with Miro API
Initially, we explored Miro’s API to programmatically extract structured content from our collaborative design boards to enable direct capturing of the board structure, sticky notes, text elements, and diagrams. However, this approach failed since Miro boards contain overlapping elements, informal annotations, and photos of slide decks embedded within them, all of which require OCR anyway.
The OCR Pivot
We pivoted to a more pragmatic approach that involved downloading Miro boards as high-quality PDFs and using Optical Character Recognition through the pytesseract library. While OCR introduces some text recognition errors, it provided a reliable, consistent method for extracting content from any visual document format without the need for additional API integrations.
This experience reinforced the lesson that data quality is everything. When our knowledge base contained poorly extracted text, both retrieval and generation quality were subpar. No amount of clever prompting could compensate for the noisy source data. It also taught us that the data pipeline is not a one-time task but an evolving task that requires continuous refinement.
Production Data Pipeline
The Python script that handles the complete ingestion workflow processes 452 documents from Google Cloud Storage, performs OCR extraction, web scraping of the YUX website, document chunking, and batch embedding generation through Vertex AI’s text-embedding-004 model.
The script includes intelligent batch processing taking Vertex AI’s rate limits into account, comprehensive error handling, and progress tracking.
The RAG Pipeline (Retrieval Meets Generation)
The RAG pipeline operates in two phases. During offline knowledge ingestion, documents stored in Google Cloud Storage undergo extraction, chunking, and embedding generation using Vertex AI’s text-embedding-004 model. These embeddings populate a FAISS (Facebook AI Similarity Search) index; an in-memory vector database that enables sub-millisecond semantic search without network latency.
Query processing follows a structured workflow. When a user submits a query through the React frontend, Firebase Authentication validates the request via ID token, then the FastAPI backend embeds the query using the same embedding model and performs FAISS similarity search to retrieve the most relevant document chunks. A detailed prompt is constructed combining the system message, retrieved context, conversation history from Firestore, the user’s query, and response length instructions, which is sent to Google’s Gemini 2.5-Pro model via Vertex AI. The model streams its response token-by-token to the frontend while both the query and response are persisted to Firestore for conversation continuity.
Cost-Performance Trade off
One of the key architectural decisions we made involved vector storage. We initially attempted to use Vertex AI’s managed Vector Search service, which has enterprise-grade indexing with minimal operational overhead. However, Vertex AI Vector Search operates on an hourly endpoint pricing model. For an internal tool with unpredictable usage patterns, these ongoing costs were difficult to justify.
Switching to FAISS eliminated this problem: we removed the operational costs entirely and actually improved performance through reduced network latency. We sacrificed the convenience of managed services for better performance and cost control.
Grounding Responses to Fight Hallucination
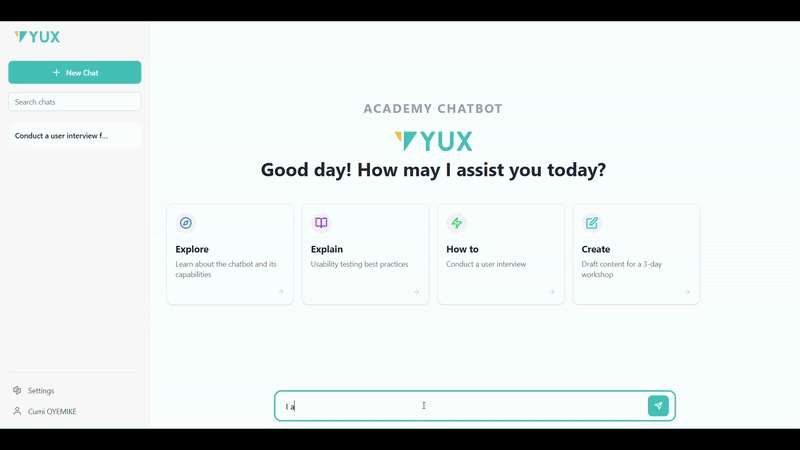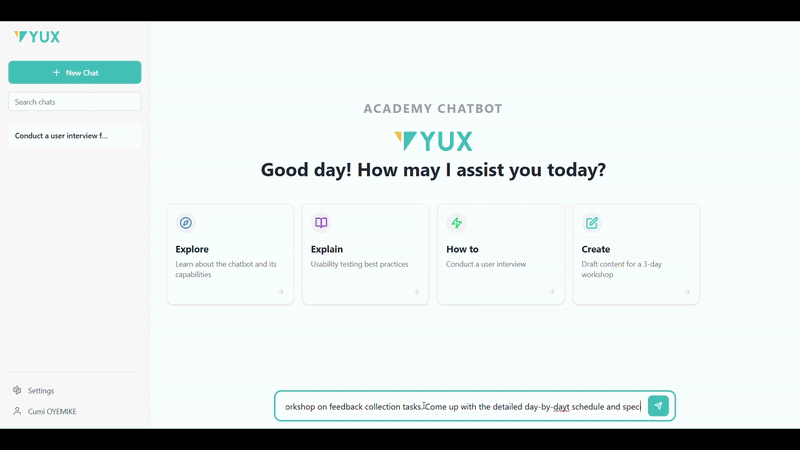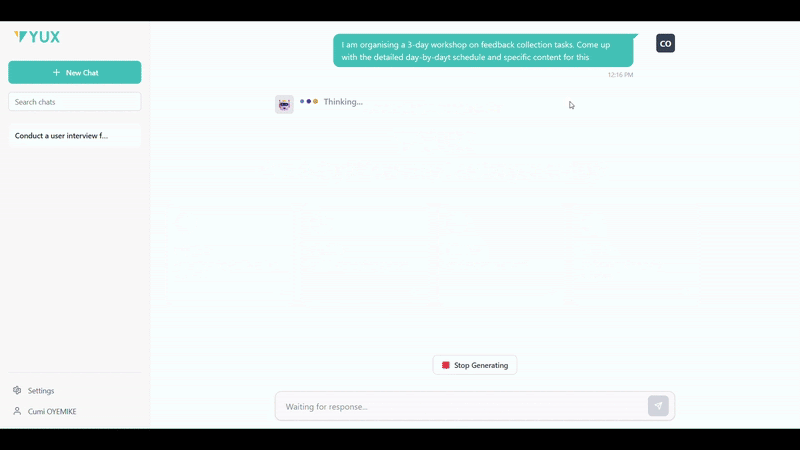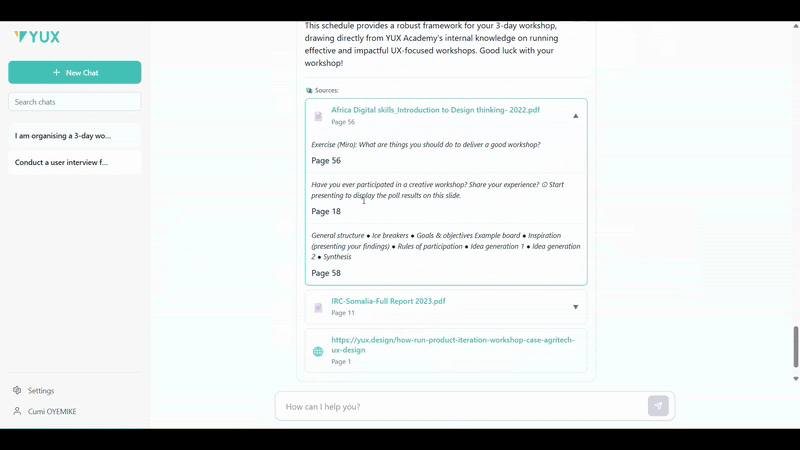
Quite importantly, this design goes a step further to ensure trustworthiness. After generating each response, the interface displays a list of the exact source documents complete with specific page numbers that were used to generate the answer. Adding this feature ensures that the assistant is not a “black box” but a transparent tool, allowing users to gain deeper context by checking the source material and build confidence in the information provided. It is the core mechanism that helps us fight against model hallucination.
Quantitative Evaluation with Ragas
With no gold standard dataset available, we implemented an automated evaluation framework to give us objective scores to track over time using the Ragas library. This system generates evaluation sets directly from our document corpus and uses an LLM-as-a-judge to score responses on metrics like Faithfulness (anti-hallucination), Answer Relevancy, and Context Precision.
Early testing showed that while answers were generally faithful, context precision sometimes lagged, meaning the system occasionally pulled in more content than necessary. This highlighted the need for ongoing monitoring and iteration on our retrieval strategies.
Conclusion
The YUX Academy AI Assistant is now a functioning service, allowing the team to easily access the previously fragmented knowledge base. Although the project is still evolving, we have already learnt crucial lessons about system design, machine learning operations (MLOps), evaluation frameworks, and what it means to build trustworthy AI.
We are now working on fine-tuning an open-source model GPT OSS-20b, as this could help the assistant better reflect YUX Academy’s unique tone and handle ambiguous queries more effectively.