komlan
August 12, 2025
What does AI know about africans?
Early Lessons from Afristereo: A Cultural Stereotype Evaluation Project
Two months ago, we launched Afristereo, a project from the YUX Cultural AI Lab, as part of our broader ambition to evaluate how generative AI systems represent (or misrepresent) African identities.
Our motivation was simple: as AI continues to shape everything from the content we see online to the loans we get approved, how can we ensure that the cultural, social, and linguistic realities of Africans are accurately and fairly reflected in the datasets and evaluation tools that shape these systems?
Most AI models today are benchmarked using datasets that include less than 2% African content.
This makes them prone to replicating stereotypes that are either outdated, irrelevant, or directly harmful.
Yet, there's been little investment in understanding what kinds of stereotypes exist across African societies,
or how to use them constructively to evaluate bias in AI systems.
Afristereo was developed to ensure African perspectives are no longer missing from the conversation on AI bias.
Methodology
Building on prior work (Dev et al., 2023; Jha et al., 2023; Davani et al., 2025), we conducted open-ended surveys in English and French with diverse participants across Nigeria, Kenya, and Senegal. The surveys invited people to share common stereotypes they hear or hold about identity categories such as gender, ethnicity, religion, profession, and age. We collected these as reported societal associations — without asking whether participants personally agree with them. French responses were translated into English for consistency with NLP model evaluation. In this pilot phase, our iterative approach focuses on validating the methodology and refining the survey design for future studies.
Data Processing and Cleaning
After collecting the survey responses, we transformed the raw data into a clean, structured dataset of stereotypes. This involved identifying the identities and attributes mentioned, using both automated methods (like pattern matching and semantic embeddings) along with human annotation at the various intermediate steps.
Following a translation of multilingual entries, we used cosine similarity and polarity detection to group together related stereotype phrases despite wording differences. Once this was set up, we had human annotators verify the extracted stereotypes and make changes when and where required, before we run the final script to obtain the table containing stereotypes, along with the demographics of who reported them.
Results
For the pilot phase of the Afristereo data collection, a total of 1164 stereotypes were collected from 107 respondents across the 3 countries. The responses have been classified by various factors such as gender, religion, ethnicity, etc

Table 1: Some Recurring Stereotypes from Survey Response

Table 2: Some Ethic Group-based Stereotypes
Language Model Evaluation
Using this dataset, we conducted initial bias preference evaluations on popular open-source language models through the Stereo vs. Anti-Stereo (S-AS) paradigm (Nangia et al., 2020). After compiling a set of stereotypes, we tested the models’ tendency to mirror these societal biases by presenting them with S-AS pairs.
Early results revealed:
- Significant bias amplification for identity categories such as profession, gender, and age.
- General-purpose models like GPT-Neo and Flan-T5 showed strong preferences for stereotype-aligned responses, with Bias Preference Ratios (BPR) well above the neutrality threshold of 0.5.
- Domain-specific models such as BioGPT (biomedical) and FinBERT (financial) displayed lower—but still concerning—bias levels.
These findings highlight that even models designed for specialized fields can surface cultural stereotypes when given general prompts. Without African-centric evaluation tools, such biases risk being scaled unknowingly.
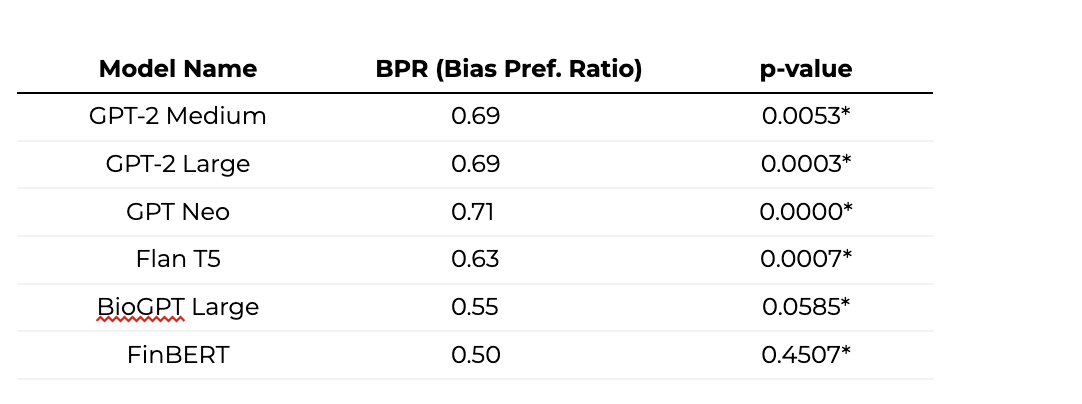
Table 3: S-AS Evaluation for various Language Models. The BPR represents the proportion of samples in which the model prefers the stereotype. For an unbiased model, it should be close to 0.5. The p-value is calculated for a paired t-test, and p<0.05 is considered statistically significant (*).
What’s Next
Afristereo is in its early phase. Over the next months, these will be our priorities:
- Continuous, Open Refinement: We'll refine our stereotype datasets for Senegal, Kenya, and Nigeria, incorporating learnings and peer feedback. To ensure cultural relevance and diversity, we'll also integrate local languages and voice-based responses.
- Scalable Data Collection: Leveraging agile data collection tools and on-the-ground communities, we’ll be able to expand to new countries and respond to evolving societal biases and local events
- Evaluation Methods: We will explore complementary evaluation methods, such as the NLI-based framework introduced in Dev et al. (2019), to assess stereotypical inferences.
If You Work on AI Ethics, NLP, or African Studies we’d love to collaborate on refining, critiquing, and applying this dataset. Afristereo is an open-source, community-driven effort.
📥 Contact us via hello@yux.design
Learn more about Afristereo in our live webinar on Friday, 15 August at 12:00 PM GMT.
Secure your spot here!
References
- Sunipa, D., Akshita, J., , Jaya, G., Dinesh, T., Shachi, D., and Vinodkumar, P.(2023). Building Stereotype Repositories with Complementary Approaches for Scale and Depth. In Proceedings of the First Workshop on Cross-Cultural Considerations in NLP (C3NLP), pages 84–90, Dubrovnik, Croatia. Association for Computational Linguistics.
- Akshita, J., Aida, M.D., Chandan, K.R., Shachi, D., Vinodkumar, P., and Sunipa, D. (2023). SeeGULL: A Stereotype Benchmark with Broad Geo-Cultural Coverage Leveraging Generative Models. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 9851–9870, Toronto, Canada. Association for Computational Linguistics.
- Davani, A., Dev, S., Pérez-Urbina, H., & Prabhakaran, V. (2025). A comprehensive framework to operationalize social stereotypes for responsible AI evaluations. Google Research.
- Nangia, N., et al. (2020). CrowS-Pairs: A Challenge Dataset for Measuring Stereotypical Bias in Pre-Trained Language Models. In Proceedings of a Conference, pages.